
HOW OUR PRODUCTS AND EXPERIENCE
Can Help Your Business
Data mining
Data analysis
Fast deployment
Data storage
Tracking tools
Customization

The Largest Source
of Insights and Happenings
Informative charts unveiling news topics coverage and 6-hours automated PDF digests
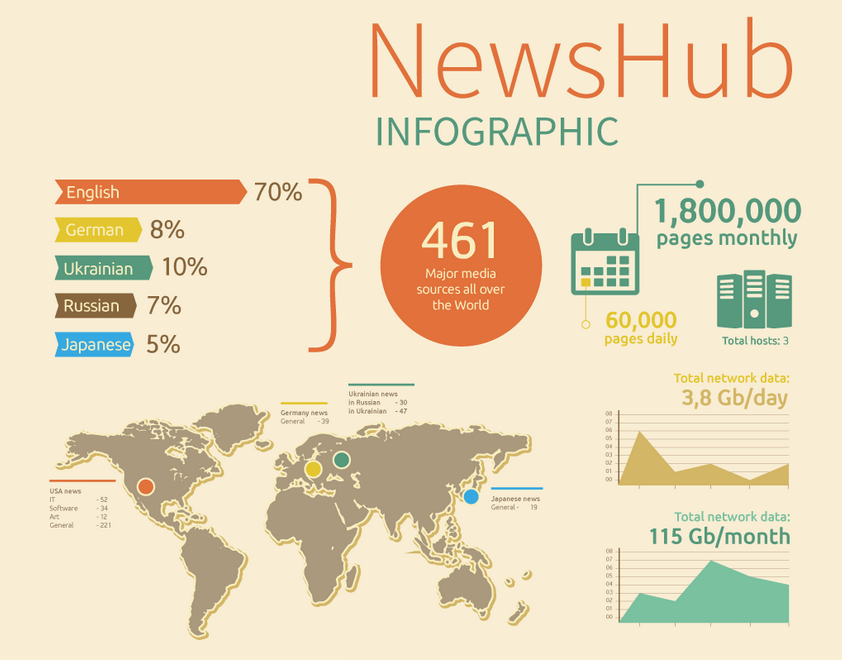
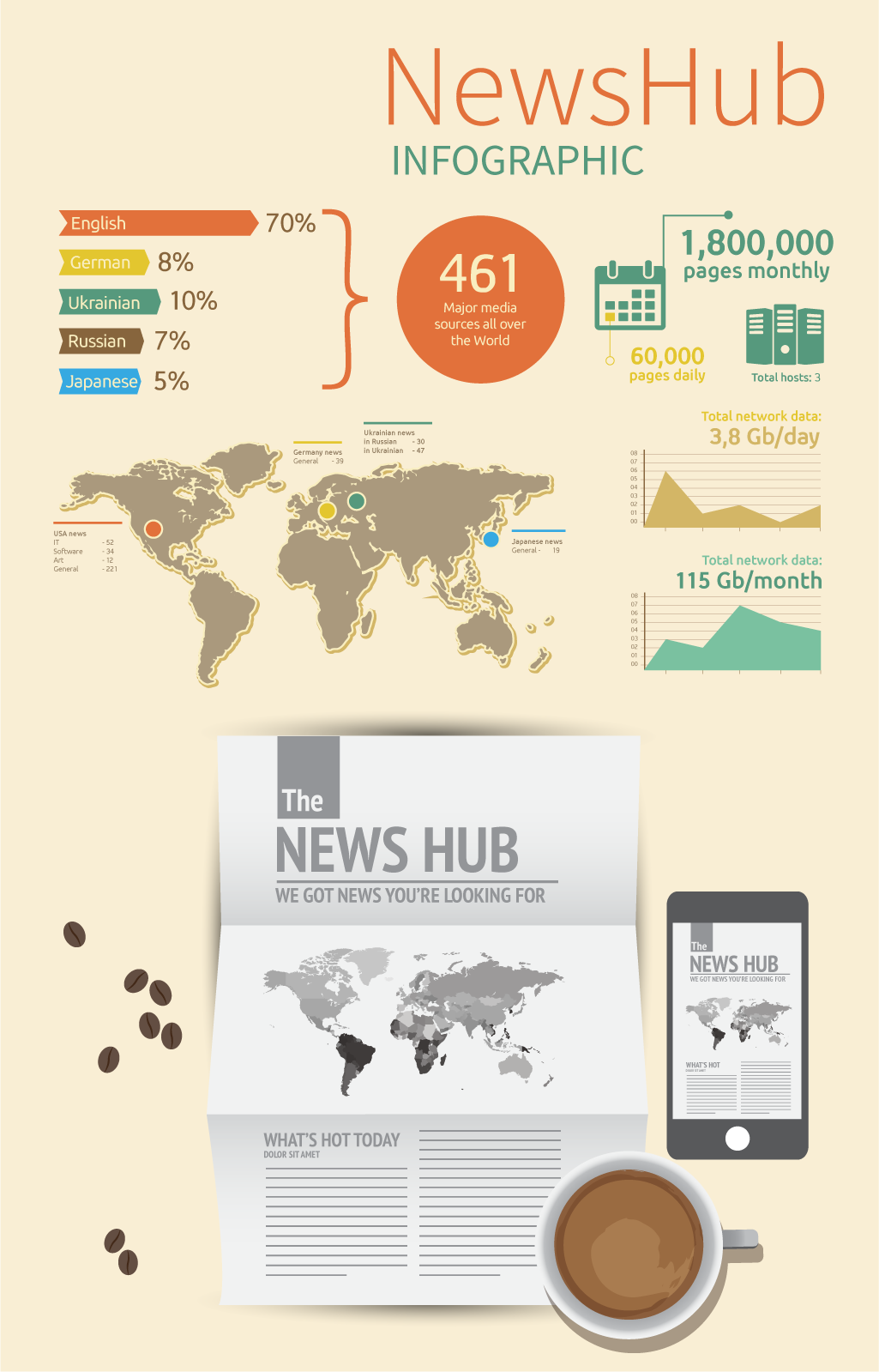
NewsHub is arguably the largest news database and the source of the latest news and happening across the globe, crawling news from over 650 online sources in different languages, with a daily extract of over 90,000 news pages. The platform allows for the generation, download, and sharing of pdf digest by email. News database currently available via API.
Personalized news discovery experience
Latest tech-related news matters to you
Many personalized news services felt too narrow, focusing too much on one type of news. What if we could do one better, and create a service that delivered news covering a broader, yet still interesting, range of topics? The cherry on top: tailoring it to the individual reader.
SNATZ uses original technology to solve the most common filtering problem - Long Tail and Filter Bubble.


Distributed Crawling Solutions for Your Business
Powerful and sophisticated engine for hierarchical networking and parallel data processing systems
Developing since 2006, Chaika used in many projects to deploy custom network mesh or distributed network cluster structure. Supports native reducing of multiple nodes results (aggregation, duplicates elimination, sorting). Has build-in powerful full-text search engine and data storage, provide transactions-less and transactional requests processing, flexible run-time changes of cluster infrastructure, multiple languages bindings for client-side APIs, and more.
Tags Reaper
explainer

Watch the video
Tags Reaper is advanced automated scraping tool we developed using top-notch technologies and out 10 yeas experience in data collecting and processing.
News Hub
Сollects over 90,000 news articles daily from 650 major news sources. We offer custom reports on topics popularity and news trends for any period of time.
Quick facts about NewsHub
- News in different languages
- Sentiments detection
- Customized graphs and charts
- 6-hours PDF digests
- API access and custom reports
- Social Networks rating analysis